
Several research groups, including ones at Google and Facebook, have found that their facial recognition systems have attained near-perfect accuracy rates, a feat that not even humans may achieve. However, these tests were performed with a dataset containing only 13,000 images, inciting the question – what happens when crowds grow and more faces are added to the mix?
“What happens if you lose your phone in a train station in Amsterdam and someone tries to steal it?” said Ira Kemelmacher-Shlizerman, an assistant professor of computer science at the University of Washington. “I’d want certainty that my phone can correctly identify me out of a million people – or 7 billion – not just 10,000 or so.” To improve the identification issue, researchers are attempting to verify accuracy of facial recognition.
Kemelmacher-Shlizerman, the project’s principal investigator, and the research team have developed the MegaFace challenge, the world’s first competition aimed at evaluating and improving the performance of face recognition algorithms at the million person scale. “We need to test facial recognition on a planetary scale to enable practical applications – testing on a larger scale lets you discover the flaws and successes of recognition algorithms,” said Kemelmacher-Shlizerman.
With more than 300 research groups working with MegaFace, the preliminary results of the exploration will be presented at the IEEE Conference on Computer Vision and Pattern Recognition on June 30. Strong contenders included Google’s FaceNet, which dropped from a near-perfect score at identifying a smaller pool of images to 75% accuracy after facing a million-person test. The accuracy rates of other algorithms that performed above 95% on a small scale dropped to as low as 33% accuracy when more images entered the experiment.
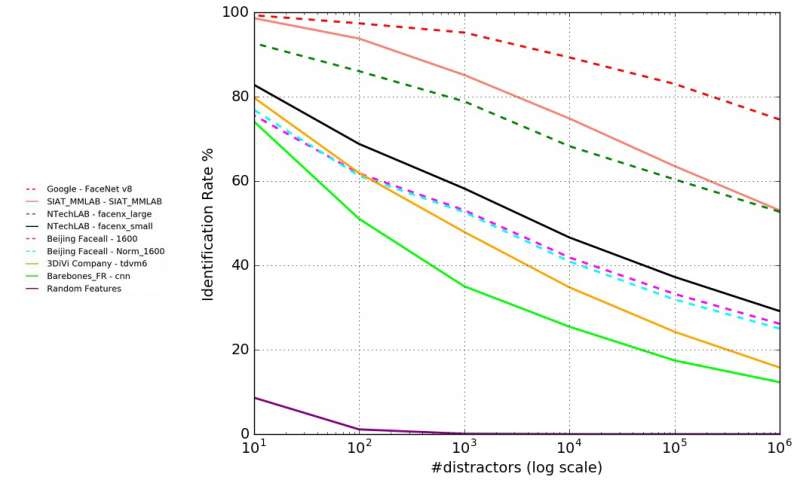
The challenge tested each algorithm’s ability to identify whether two photos were of the same person. The test also evaluated how accurately an algorithm could match a photo of one person to a different image of the same person among a million “distractors.” Other factors outlined in the research factor also include people’s age and pose invariance (does a person’s pose in a photo affect the algorithm’s ability to identify him or her?). The ongoing results posted on the project website show that some algorithms “learned” how to find correct images out of larger databases, outperforming those limited to smaller datasets.
The team will next gather half a million identities, all with several photographs, that will create a dataset used to train facial recognition algorithms.
“State-of-the-art deep neural network algorithms have millions of parameters to learn and require a plethora of examples to accurately tune them,” said Aaron Nech, a UW computer science and engineering master’s student working on the project. “Having diversity in the data, such as the intricate identity cues found across more than 500,000 unique individuals, can increase algorithm performance by providing examples of situations not yet seen.”
Advertisement
Learn more about Electronic Products Magazine




