BY VICTOR CHENG
Senior Software Engineer for Automotive Processors, Texas Instruments
www.ti.com
Self-driving cars and their computer-vision systems have received a lot of news coverage, making it clear how difficult it can be to design a robust vision system that performs well in any environmental condition. There are several key elements that all designers should consider as they develop these complex automotive vision systems. These include sensor redundancy, low-light vision processing, and faulty sensor detection.
The importance of sensor redundancy
For each position around the car that uses a vision system for object detection, there should be multiple cameras (at least two) pointing to the line of sight. This setup should be in place even when the vision algorithms only need monovision data.
Sensor multiplicity allows for failure detection of the primary camera by comparing images with auxiliary cameras. The primary camera feeds its data to the vision algorithm. If the system detects a failure of the primary camera, it should be able to reroute one of the auxiliary cameras’ data to the vision algorithm.
With multiple cameras available, the vision algorithm should also take advantage of stereo vision. Collecting depth data at a lower resolution and a lower frame rate will conserve processing power. Even when processing is mono-camera by nature, depth information can speed up object classification by reducing the number of scales that need processing based on the minimum and maximum distances of objects in the scene.
For example, the Texas Instruments (TI) line of TDAx automotive processors are equipped with the necessary technology to handle at least eight camera inputs and to perform state-of-the-art stereo-vision processing through a Vision AcceleratorPac to meet such requirements. The Vision AcceleratorPac contains multiple embedded vision engines (EVEs) that excel in the type of single-instruction multiple-datapath (SIMD) operations used in a stereo-vision system’s correspondence-matching algorithm.
The importance of low-light vision, reliance on an offline map, and sensor fusion
Low-light vision processing requires a mode of processing different than the one used in daylight. Images captured in low-light conditions have a low signal-to-noise ratio, and structured elements such as edges are buried beneath the noise. In low-light conditions, vision algorithms should rely more on blobs or shapes rather than edges. Typical computer-vision algorithms such as the histogram of oriented gradients (HOG)-based object classifications rely mostly on edges because these features are predominant in daylight. But cars equipped with such vision systems will have problems detecting other vehicles or pedestrians on a poorly lit road at night.
If the system detects low-light conditions, the vision algorithm should switch to a low-light mode. This mode could be implemented using a deep-learning network that is trained using low-light images only. Low-light mode should also rely on data from an offline map or an offline worldview. A low-light vision algorithm can provide cues to find the correct location on a map and reconstruct a scene from an offline worldview, which should be enough for navigation in static environments.
In dynamic environments, however, with moving or new objects that were not previously recorded, fusion with other sensors (LiDAR, radar, thermal cameras, etc.) will be necessary to ensure optimum performance by taking advantage of the respective strength of each sensor modality. For instance, LiDAR will work equally well in the day or night but cannot distinguish color. Cameras have poor vision in low-light conditions but provide color information to algorithms that detect red lights and traffic signs. Both of these sensors will perform badly in the presence of rain, snow, and fog. Radars can be used in bad weather, but they don’t have enough spatial resolution to accurately detect the location and size of an object.
You can see that the information provided by each sensor, if used individually, is incomplete or uncertain. To reduce this uncertainty, a fusion algorithm combines the data collected from these different sensors.
This is a benefit of using a heterogeneous architecture design. TI’s TDA2x processors, as an example, can tackle the diversity of the processing needed for sensor data acquisition, processing, and fusion thanks to three different cores (EVE, digital signal processor [DSP], and microcontroller [MCU]) with different architectures. See Fig. 1 for details of the functional mapping.
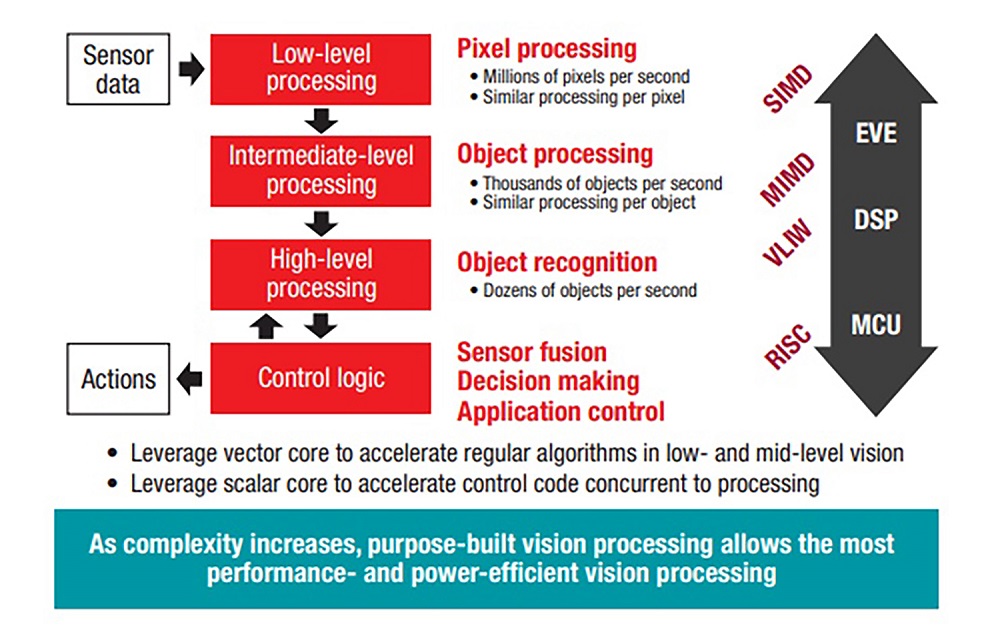
Fig. 1: A heterogeneous system-on-chip (SoC) concept achieves the highest processing performance and power efficiency.
Low-light conditions require the use of high-dynamic-range (HDR) sensors. These HDR sensors output multiple images for the same frame with different exposure/gain values. To be usable, these images must be combined/merged into one. Such merging algorithms are usually computationally intensive, but TI’s TDA2P and TDA3x processors have a hardware image signal processor (ISP) capable of processing HDR images through a pipeline made of merging, noise filtering, flicker mitigation, demosaicing, and sharpness enhancement blocks.
In addition to offloading image signal processing tasks, having an ISP integrated into the vision processor instead of the sensor has the advantage of limiting power dissipation and heat generation in the camera, which helps increase the image quality. This ISP is powerful enough to handle up to eight 1-MP cameras, which makes it a good fit for surround-view applications.
The aim of the ISP is to produce the highest-quality image possible before passing it to the computer-vision algorithm so that the latter can perform more optimally. But even when the image quality is not ideal, recent developments in computer vision help mitigate the optical effects caused by a bad operating environment.
Indeed, over the last decade, deep learning, an artificial intelligence technology, has been able to tackle the most challenging computer-vision problems. But due to its heavy demand on computational power, deep learning has been mainly confined to the cloud-computing and data-center industries.
Researchers have focused on developing deep-learning networks light enough to run on embedded systems without a loss of quality. To support this revolutionary technology, TI created the TI Deep Learning (TIDL) library. Implemented using the Vision AcceleratorPac, TIDL can take deep-learning networks designed with the Caffe or TensorFlow frameworks and execute them in real time within a 2.5-W power envelope. Semantic segmentation (Fig. 2 ) and single-shot detector are among the networks successfully demonstrated on TDA2x processors.

Fig. 2: Semantic segmentation using TIDL on a TDA2x SoC.
To complement its vision technology, TI has been ramping up efforts to develop radar technology tailored for advanced driver assistance systems (ADAS) and the autonomous driving market. These include the following:
- Automotive radar millimeter-wave (mmWave) sensors using complementary metal-oxide semiconductor (CMOS) technology. AWR1xx sensors for mid- and long-range radars integrate radio-frequency (RF) and analog functionality with digital control capability into a single chip. Including these capabilities in one chip reduces typical radar system sizes by 50%. Additionally, the smaller form factor of the sensor requires less power and can withstand higher ambient temperatures.
- A software development kit running on TDAx processors that implements the radar signal processing chain enables the processing of as many as four radar signals. The radar signal processing chain includes 2D fast Fourier transform (FFT), peak detection, and beamforming stages, enabling object detection. Thanks to its high configurability, the radar signal processing chain can support different automotive applications, including long range used in adaptive cruise control and short range used in parking assistance.
The importance of faulty sensor detection and a fail-safe mechanism
In a world moving toward autonomous driving, a faulty sensor or even dirt can have life-threatening consequences because a noisy image can fool the vision algorithm and lead to incorrect classifications. There will likely be a greater focus applied to developing algorithms that can detect invalid scenes produced by a faulty sensor. The system can implement fail-safe mechanisms such as activating the emergency lights or gradually bringing the car to a halt.
For instance, TDAx devices feature a learning-based algorithm that uses sharpness statistics from the H3A engine to detect obstructions. The H3A provides a block-by-block sharpness score, thus providing fine-level statistics to the algorithm. This technique enables the detection of the kind of camera obstruction scenarios shown in Fig. 3 .

Fig. 3: Example of lens obstruction detection.
Conclusion
Engineers who are designing automotive vision systems for self-driving cars face many challenges as requirements for robustness increase with each level of autonomy. Fortunately, the number of tools available to tackle all of these issues is always growing, and continuous progress in sensor technology, processor architectures, and algorithms will eventually lead to self-driving cars.
TI offers a range of products targeted at the automotive market, including its line of TDAx processors, deep-learning software library, and radar sensors. These products enable the design of robust front-camera, rear-camera, surround-view, radar, and fusion applications that are the building blocks of today’s ADAS technology and tomorrow’s foundation for autonomous cars.
Advertisement
Learn more about Texas Instruments




