
By Tom Doyle, CEO and founder, Aspinity
International Data Corp. (IDC) estimates that 41.6 billion connected internet of things (IoT) devices will generate an astounding 70.4 zettabytes of data by 2025. That represents a compound annual growth rate of 28.7% for data created by connected devices over the 2018-2025 forecast period, according to the research firm. Much of that data will contain personal and private information, such as your location, your heart rate, and more and more often – your voice.
That’s because the use of voice-first devices is surging, driven by the desire for a convenient voice user interface that simplifies human-machine interaction. But as is often the case, this convenience comes at a price — the potential loss of user privacy.
Why is our personal data vulnerable?
The problem lies in the inherent design of always-on, always-connected voice-first devices. They require an internet connection because understanding commands spoken in natural language requires the audio processing capabilities of powerful cloud platforms such as Amazon Alexa and Microsoft Cortana.
In recent months, many of the biggest cloud technology companies have acknowledged gathering at least some small percentage of voice commands to improve the overall performance of their speech recognition. And while the intention was never nefarious, these recordings threaten user privacy as they may reveal personal habits, location or other private information that was not intended for sharing.
From the cloud to the edge
To address concerns over user privacy, device designers have been looking for ways to transmit less data to the cloud by bringing more of the audio processing into the device. Moving more processing to the edge is a trend across the IoT industry, and not just for voice data but for other types of sensitive or proprietary data as well, e.g., acoustic events and vibration.
Yet designers have realized limited success because the level of data processing needed to support such complex processing also requires significant power. It is also exceptionally difficult to integrate additional local audio processing into a device powered by just a small battery because today’s voice-first devices require the continuous digitization and analysis of all incoming sound data. Unfortunately, this is a necessary evil for legacy signal-processing architectures that are always listening for the wake word.
Tackling this power issue is critical to an effective edge processing solution that can make voice assistants less reliant on the cloud, keeping private data more secure.
Workarounds provide incremental improvements
Design engineers have tried workarounds to decrease power consumption in an always-listening system, including duty cycling and reducing the power of each individual component in the audio signal chain that handles the data. Both approaches are problematic. Duty cycling, or turning on and off the data-gathering system to save power, comes at the expense of system accuracy for higher-bandwidth applications, such as sound, where all input is critical and must be processed. This is a deal-breaker for many users, who are unwilling to sacrifice performance for convenience.
And while it’s true that using a lower-power microphone with a sleep mode or a lower-power DSP or microcontroller can reduce power, the battery-life savings they afford to an always-on connected device is incremental at best. The reality is that these approaches don’t address the root cause of the power problem: too much data.
To truly tackle the power problem, we need a system solution, not a component solution. We must move to a more efficient edge architecture that intelligently minimizes the amount of data that moves through the system, focusing system energy on just the important audio information, which in this case is voice.
Machine learning in analog
For device designers to move more of the audio processing capability from the cloud to the edge without reducing battery life, we need to embrace a fundamentally new architectural approach: Determine what data is important enough to warrant high-power processing earlier in the signal chain using minimal energy. In short, we need to move away from the “digitize-first” approach that has dominated voice wake-up device architecture since the first voice-first applications.
The digitize-first model requires digitizing 100% of the incoming microphone data for wake word analysis. Because voice is spoken only randomly and sporadically, up to 90% of the system power that is used to digitize and analyze the audio signal is wasted searching for a wake word when there is only noise.
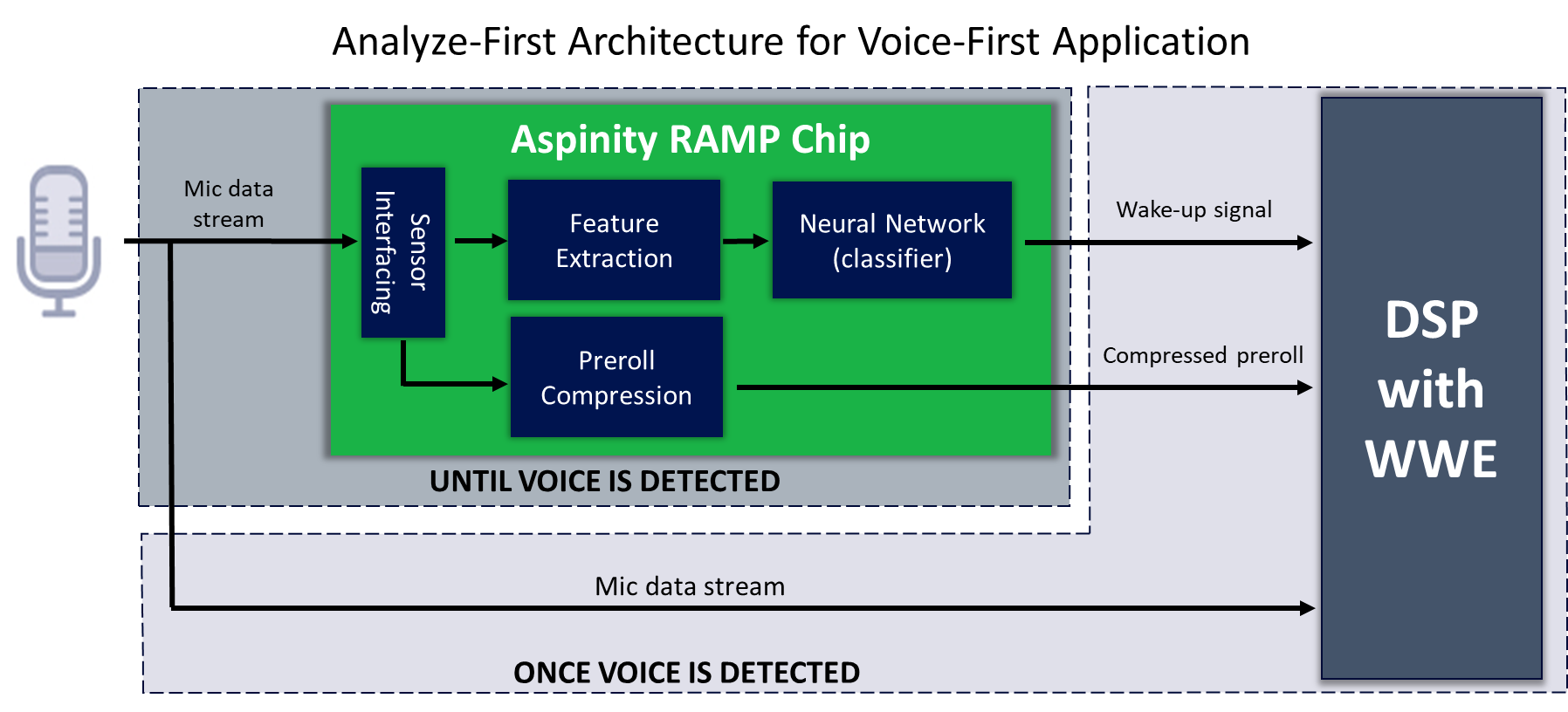
A new ultra-low-power analog edge-processing technology called Reconfigurable Analog Modular Processor (RAMP) is changing this paradigm. For the first time, device designers can use low-power analog machine learning to detect which data are important for further processing and analysis prior to data digitization. In an “analyze-first” architecture, the RAMP chip allows the higher-power-processing components in the system to stay asleep until voice has actually been detected, and only then does it wake them to “listen” for a possible wake word.
The analyze-first architecture is so efficient that it uses 10× less power than a digitize-first-based approach to always-on listening. That’s the difference between a portable smart speaker that runs for a month instead of a week on single battery charge. More importantly, it’s the difference between an always-listening device that can indiscriminately record and send all sound data to the cloud, and one that has the localized intelligence to select and send only the relevant data, reducing the user’s vulnerability to an inadvertent loss of private data.
Balancing convenience with privacy
The trade-off between making our lives easier and keeping our personal information private is a choice that we are asked to make many times per day in a hundred different ways. Bringing more audio processing capability to the device is the first step toward delivering more secure voice-first solutions.
But to succeed in this effort, we must change the paradigm: Use a lower-power architecture that more efficiently handles data. That way all 70.4 zettabytes of data collected by IoT devices in 2025 don’t have to be digitized, processed, and sent to the cloud. A better balance between cloud and edge processing is a better balance between convenience and privacy, and that’s a win for everyone.
For more information on the analyze-first architectural approach to voice-first devices, please view our video .
About the author
Tom Doyle is CEO and founder of Aspinity. He brings more than 30 years of experience in operational excellence and executive leadership in analog and mixed-signal semiconductor technology to Aspinity. Prior to Aspinity, Tom was group director of Cadence Design Systems’ analog and mixed-signal IC business unit, where he managed the deployment of the company’s technology to the world’s foremost semiconductor companies. Previously, Tom was founder and president of the analog/mixed-signal software firm, Paragon IC solutions, where he was responsible for all operational facets of the company including sales and marketing, global partners/distributors, and engineering teams in the US and Asia. Tom holds a B.S. in Electrical Engineering from West Virginia University and an MBA from California State University, Long Beach. For more information, visit: www.aspinity.com
Advertisement
Learn more about Electronic Products Magazine




