Startup EdgeCortix Inc. recently launched its next-generation SAKURA-II edge AI accelerator, designed for processing generative AI (GenAI) workloads at the edge with minimal power consumption and low latency. This platform is paired with the company’s second-generation dynamic neural accelerator (DNA) architecture to address the most challenging GenAI tasks in the industry.
EdgeCortix, headquartered in Japan, introduced its first-generation AI accelerator, SAKURA-I, in 2022, claiming over 10× performance-per-watt advantage over competing AI inference solutions based on GPUs for real-time edge applications. It also announced the open-source release of its MERA compiler software framework.
The company has leveraged feedback from customers using its first-generation silicon to deliver an updated architecture that offers future-proofing in terms of activation functions and support for a changing AI model landscape, while adding new features, such as sparse computation, advanced power management, mixed-precision support and a new reshaper engine. It also offers better performance per watt and higher memory capacity in multiple form factors.

SAKURA-II edge AI accelerator (Source: EdgeCortix Inc.)
The SAKURA-II accelerator or co-processor is a compelling solution, with a performance of 60 trillion operations per second (TOPS) with 8 W of typical power consumption, mixed-precision support and built-in memory-compression capabilities, said Sakyasingha Dasgupta, CEO and founder of EdgeCortix. Whether running traditional AI models or the latest GenAI solutions at the edge, it is one of the most flexible and power-efficient accelerators, he added.
SAKURA-II can handle complex tasks, such as large language models (LLMs), large vision models (LVMs) and multimodal transformer-based applications in the manufacturing, Industry 4.0, security, robotics, aerospace and telecommunications industries. It can manage multi-billion parameter models, such as Llama 2, Stable Diffusion, DETR and ViT, within a typical power envelope of 8 W.
In a nutshell, the SAKURA-II accelerator is optimized for GenAI and real-time data streaming with low latency. It delivers exceptional energy efficiency (touted as more than 2× the AI compute utilization of other solutions), higher DRAM capacity—up to 32 GB—to handle complex vision and GenAI workloads, and up to 4× more DRAM bandwidth than other AI accelerators and advanced power management for ultra-high-efficiency modes. It also adds sparse computation to reduce the memory bandwidth, a new integrated tensor reshaper engine to minimize the host CPU load, arbitrary activation function and software-enabled mixed precision for near-F32 accuracy.
EdgeCortix’s solutions aim to reduce the cost, power and time of data transfer by moving more AI processing to the site of data creation. The edge AI accelerator platform addresses two big challenges due to “the explosive growth of the latest-generation AI models,” Dasgupta said. The first challenge is the rising computational demand due to these “exponentially growing models” and the resulting rise in hardware costs, he said.
The cost of deploying a solution or the cost of operation, whether it is in a smart city, robotics or the aerospace industry in an edge environment, is critically important, he added.
The second challenge is how to build more power-efficient systems. “Unfortunately, the majority of today’s AI models are a lot more power-hungry in terms of both electricity consumption as well as carbon emissions,” he said. “So how do we build systems with a software and hardware combination that is a lot more energy-efficient, especially for an edge environment that is constrained by power, weight and size? That really drives who we are as a company.”
The company’s core mission, Dasgupta said, is to deliver a solution that brings near-cloud-level performance to the edge environment, while also delivering orders of magnitude better power efficiency.
Performance per watt is a key factor for customers, Dasgupta added, especially in an edge environment, and within that, real-time processing becomes a critical factor.
Data at the edge
Looking at the data center versus edge landscape, most of the data consumed is being generated or processed, especially enterprise data, at the edge and that will continue into the future, Dasgupta said.
According to IDC, 74 zettabytes of data will be generated at the edge by 2025. Moving this enormous amount of data continuously from the edge to the cloud is expensive both in terms of power and time, he adds. “The fundamental tenet of AI is how we bring computation and intelligence to the seat of data creation.”
Dasgupta said EdgeCortix has achieved this by pairing its design ethos of software first with power-efficient hardware to reduce the cost of data transfer.
The latest product caters to the GenAI landscape as well as across multi-billion parameter LLMs and vision models within the constraint of low-power requirements at the edge across applications, Dasgupta said. The latest low-power GenAI solution targets a range of verticals, from smart cities, smart retail and telecom to robotics, the factory floor, autonomous vehicles and even military/aerospace.
The platform
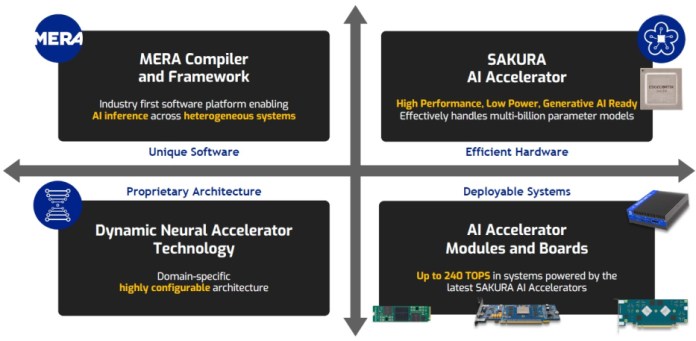
The software-driven unified platform is comprised of the SAKURA AI accelerator, MERA compiler and framework, DNA technology and the AI accelerator modules and boards. It supports both the latest GenAI and convolutional models.
Designed for flexibility and power efficiency, SAKURA-II offers high memory bandwidth, high accuracy and compact form factors. By leveraging EdgeCortix’s latest-generation runtime reconfigurable neural processing engine, DNA-II, SAKURA-II can provide high power efficiency and real-time processing capabilities while simultaneously executing multiple deep neural network models with low latency.
Dasgupta said it is difficult to put a number to latency because it depends on the AI models and applications. Most applications, depending on the larger models, will be below 10 ms, and in some cases, it could be in the sub-millisecond range.
The SAKURA-II hardware and software platform delivers flexibility, scalability and power efficiency. (Source: EdgeCortix Inc.)
The SAKURA-II platform, with the company’s MERA software suite, features a heterogeneous compiler platform, advanced quantization and model calibration capabilities. This software suite includes native support for development frameworks, such as PyTorch, TensorFlow Lite and ONNX. MERA’s flexible host-to-accelerator unified runtime can scale across single, multi-chip and multi-card systems at the edge. This significantly streamlines AI inferencing and shortens deployment times.
In addition, the integration with the MERA Model Zoo offers a seamless interface to Hugging Face Optimum and gives users access to an extensive range of the latest transformer models. This ensures a smooth transition from training to edge inference.
“One of the exciting elements is a new MERA model library that creates a direct interface with Hugging Face where our customers can bring a large number of current-generation transformer models without having to worry about portability,” Dasgupta said.

MERA Software supports diverse neural networks, from convolutions to the latest GenAI models. (Source: EdgeCortix Inc.)
By building a software-first—Software 2.0—architecture with new innovations, Dasgupta said the company has been able to get an order or two orders of magnitude increase in peak performance per watt compared with general-purpose systems, using CPUs and GPUs, depending on the application.
“We are able to preserve high accuracy [99% of FP32] for applications within those constrained environments of the edge; we’re able to deliver a lot more performance per watt, so better efficiency, and much higher speed in terms of the latency-sensitive and real-time critical applications, especially driven by multimodal-type applications with the latest generative AI models,” Dasgupta said. “And finally, a lower cost of operations in terms of even performance per dollar, preserving a significant advantage compared with other competing solutions.”
This drives edge AI accelerator requirements, which has gone into the design of the latest SAKURA product, Dasgupta said.
More details on SAKURA-II
SAKURA-II can deliver up to 60 TOPS of 8-bit integer, or INT8, performance and 30 trillion 16-bit brain floating-point operations per second (TFLOPS), while also supporting built-in mixed precision for handling next-generation AI tasks. The higher DRAM bandwidth targets the demand for higher performance for LLMs and LVMs.
Also new for the SAKURA-II are the advanced power management features, including on-chip power gating and power management capabilities for ultra-high-efficiency modes and a dedicated tensor reshaper engine to manage complex data permutations on-chip and minimize host CPU load for efficient data handling.
Some of the key architecture innovations include sparse computation that natively supports memory footprint optimization to reduce the amount of memory required to move large amounts of models, especially multi-billion-parameter LLMs, Dasgupta said, which has a big impact on performance and power consumption.
The built-in advanced power management mechanisms can switch off different parts of the device while an application is running in a way that can trade off power versus performance, Dasgupta said, which enhances the performance per watt in applications or models that do not require all 60 TOPS.
“We also added a dedicated IP in the form of a new reshaper engine on the hardware itself, and this has been designed to handle large tensor operations,” Dasgupta said. This dedicated engine on-chip improves power as well as reduces latency even further, he added.
Dasgupta said the accelerator architecture is the key building block of the SAKURA-II’s performance. “We have much higher utilization of our transistors on the semiconductor as compared with some of our competitors, especially from a GPU perspective. It is typically somewhere on average 2× better utilization, and that gives us much better performance per watt.”
SAKURA-II also adds support for arbitrary activation functions on the hardware, which Dasgupta calls a future-proofing mechanism, so as new types of arbitrary activation functions come in, they can be extended to the user without having to change the hardware.
It also offers mixed-precision support on the software and hardware to trade off between performance and accuracy. Running some parts of a model at a higher precision and others at a reduced precision, depending on the application, becomes important in multimodal cases, Dasgupta said.
SAKURA-II is available in several form factors to meet different customer requirements. These include a standalone device in a 19 × 19-mm BGA package, a M.2 module with a single device and PCIe cards with up to four devices. The M.2 module offers 8 or 16 GB of DRAM and is designed for space-constrained applications, while the single (16-GB DRAM) and dual (32-GB DRAM) PCIe cards target edge server applications.
SAKURA-II addresses space-constrained environments with the M.2 module form factor, supporting both x86 or Arm systems, and delivers performance by supporting multi-billion-parameter models as well as traditional vision models, Dasgupta said.
“The latest-generation product supports a very powerful compiler and software stack that can marry our co-processor with existing x86 or Arm systems working across different types of heterogeneous landscape in the edge space.”

SAKURA-II M.2 module (Source: EdgeCortix Inc.)
The unified platform also delivers a high amount of compute, up to 240 TOPS, in a single PCIe card with four devices with under 50 W of power consumption.
Dasgupta said power has been maintained at previous levels with the SAKURA-II, so customers are getting a much higher performance per watt. The power consumption is typically about 8 W for the most complex AI models and even less for some applications, he said.
SAKURA-II will be available as a standalone device, with two M.2 modules with different DRAM capacities (8 GB and 16 GB), and single- and dual-device low-profile PCIe cards. Customers can reserve M.2 modules and PCIe cards for delivery in the second half of 2024. The accelerators, M.2 modules and PCIe cards can be pre-ordered.
Advertisement




