Voice is an increasingly important human-to-machine interface (HMI) option for IoT devices and personal digital assistants, but it requires expertise in acoustic hardware and algorithm development for accurate results and a positive end-user experience. To simplify and accelerate the voice-service integration process, Microsemi has introduced the AcuEdge Development Kit for Amazon Alexa Voice Service (AVS).
“Voice is the way forward,” Farhad Mafie, vice president of worldwide corporate communications & product marketing at Microsemi, told Electronic Products. “It makes it easier to ask for information so there’s more demand for information.” While this creates an opportunity for the designers developing front-end products for IoT, Industrial IoT (IIoT), and automated assistance, it also requires that the back-end intelligence has to be more intuitive. “[Artificial intelligence (AI)] can do this,” said Mafie.
While Amazon, Google, Apple, Microsoft, Nuance, and others work on making the back end more intuitive, Microsemi is focused on helping developers get accurate voice data into the system and to the cloud, starting with Amazon’s AVS.
The kit features Microsemi’s ZL38063 Timberwolf multi-mic audio processor on an evaluation that also has two microphones that can operate in both 180˚ and 360˚ audio pickup modes (Fig. 1 ). The board comes with a Raspberry Pi connector for fast setup and development, as well as a board and speaker stand to quickly evaluate performance.
Fig. 1: The AcuEdge dev kit is based on Microsemi’s Timberwolf processor and provides a platform for designers to develop and implement Alexa Voice Services on any connected device. (Image source: Microsemi Corporation)
Along with the hardware, Microsemi brings its experience in voice recognition, which includes an appreciation of the difference between audio for the human ear and audio for machines. “When we look back, we see that audio was made to be extremely pleasant to the human ear,” said Shahin Sadeghi, marketing director at Microsemi. “Speech recognition engines are not human ears: The shaping of audio for ears causes havoc for a detector. Acoustic echo cancellation is completely different for Alexa.”
Microsemi breaks speech recognition down to automatic speech recognition (ASR) and automatic speech recognition assist (ASR Assist) (Fig. 2 ). ASR refers to a machine or program’s ability to receive and interpret spoken commands. ASR Assist refers to audio enhancements for HMI — in particular, trigger word detection, such as “Hi, Alexa”.
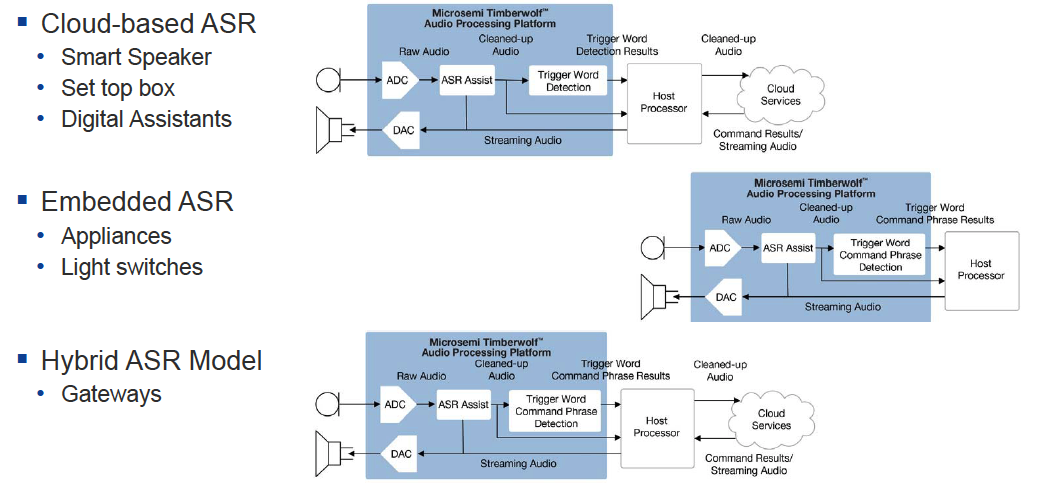
Fig. 2: There are two main types of automatic speech recognition: ASR and ASR Assist. (Image source: Microsemi Corporation)
ASR Assist also includes “barge in,” meaning that trigger words can be detected when an Alexa-enabled terminal or audio system speaker is in playback mode. Other ASR Assist features that Microsemi brings to the table with ASR Assist in the AcuEdge (ZLK38AVS) kit include beamforming, compressor/limiter/expander (CLE) microphone pickup, ambient noise reduction, and far-field mic capability. Note that the Raspberry Pi runs the Amazon AVS client and Alexa wake word detection, while the Timberwolf performs all the front-end audio processing to ensure accuracy.
Once deployed, the Timberwolf processor is field-programmable for firmware updates. Available now, AcuEdge costs $299.
Advertisement
Learn more about Microsemi




