
The idea is growing that the next generation of user interfaces, especially in consumer devices, will be voice control. A number of chip vendors recently have released devices that provide front-end audio pre-processing for cloud-based voice recognition like Alexa and Google Home. Cirrus Logic is the latest, but by no means least, to join the chorus of voice-processing chip providers.
Voice has numerous advantages as a user interface. A design can do without buttons, keyboards, lights, or displays and still provide a rich range of actions from which a user can select. This allows the design to be quite small or of unusual shape without compromising interactivity. There also need not be physical contact between user and device, which widens the array of placement options and allows hands-free operation.
A voice interface must overcome many challenges, though. Even before the computationally heavy AI of speech recognition, audio processing to remove echoes and reverberation, provide noise reduction, provide gain control, and cancel out any audio that the device itself is generating is needed. Fortunately, those challenges have been overcome. Cloud-based speech recognition services such as Amazon’s Alexa Voice Service (AVS) and Google Assistant are providing the back end, and voice-processing chips are providing the front end.
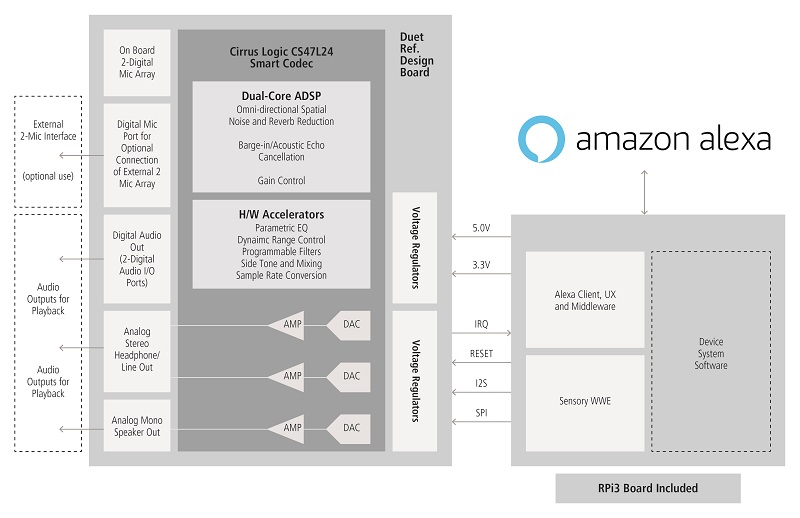
Cirrus Logic is the most recent entry in a growing chorus of voice-processing suppliers, releasing its voice-capture development kit earlier this month. Based on the company’s CS47L24 smart codec, CS7250B digital MEMS microphones, and SoundClear audio-processing algorithms, the kit’s voice-capture board provides all the pre-processing needed to prepare an audio signal for AVS handling. The capture board connects as a shield to a Raspberry Pi 3, which provides the interactivity with the AVS service and runs the software monitoring the audio feed for the “wake word.” The offering is optimized for low-power designs and offers options to ease its inclusion into prototypes of varying form factors.
What’s different about the Cirrus offering is the company’s long-standing involvement with audio processing, which has enabled it to match three key elements of the design — the microphones, the codec, and the software — all their own products. The MEMS microphones, for instance, have an ultra-low noise floor and wide (130-dB) dynamic range that, together, provide an especially clean signal on which the processing can operate.
The SoundClear software provides operations such as noise suppression, echo cancellation, audio beamforming using multiple microphone input signals, and voice enhancement. The codec provides not only the DSP functionality needed to run the software, it includes the ADCs, DACs, and power amplifiers needed to both capture and play back audio as well as power the speakers. And because the same device is handling both audio capture and playback, it is able to cancel out its own playback when listening for commands, facilitating “barge-in” commands without requiring users to shout over any playback going on.
At a price of $400 for the development kit, it is not targeting hobbyists or casual developers. Rather, it is intended to provide serious product development efforts with a springboard to get voice-control development off to a quick start.
Related articles:
XMOS and Qualcomm launch voice-processing dev kits for cloud-based speech recognition
How to build your own Amazon Echo — or something like it
Advertisement
Learn more about Electronic Products Magazine




