Multithreaded processors and multicore chips are becoming the norm
By KEVIN D. KISSELL
MIPS Technologies
Mountain View, CA
http://www.mips.com
Is multithreading better than multicore? One might as well ask whether a diesel engine is better than four-wheel drive. The best vehicle for a given application might have one, the other, or both. Or neither. They are independent—but complementary—design decisions. With multithreaded processors and multicore chips becoming the norm, architects and designers need to understand their respective attributes, advantages, and disadvantages.
Tapping concurrency as a resource
Multiprocessor, or multicore, systems exploit concurrency to spread work around a system, with as many tasks running at the same time as there are processors. This can improve absolute performance, cost, or power/performance. Clearly, once one has built the fastest single processor possible in a given technology, the only way to get even more compute power is to use more than one. More subtly, if a load that would saturate a 1-GHz processor could be evenly spread across four processors, those processors could be run at roughly 250 MHz each. If each 250-MHz processor is less than one-quarter the size of the 1-GHz processor, or consumes less than ¼ the power, either of which may be the case because of the nonlinear cost of higher operating frequencies, the multicore system might be more economical.
Many designers of embedded SoCs are already exploiting concurrency with multiple cores. Unlike general-purpose workstations and servers, whose workload is variable and unknowable to system designers, it’s often possible to decompose a set of embedded device functions into specialized tasks and assign tasks across multiple processors, each of which can be specified and configured optimally for a specific job.
Multithreaded processors exploit the concurrency of multiple tasks in a different way. Instead of a system-level technique to spread CPU load, multithreading is a processor-level optimization to improve efficiency. Multithreaded architecture is driven to a large degree by the observation that single-threaded high-performance processors are stalled a surprising amount of the time. When data from memory are required for a program to advance, and RAM has a cycle time tens of times slower than that of the processor, a single-threaded processor must stall until the data are returned.
The multithreading hypothesis can be stated as: If latencies prevent a single task from keeping a processor pipeline busy, then a single pipeline should be able to complete more than one concurrent task in less time than it would take to run the tasks serially. This means running more than one task’s instruction stream, or thread, at a time, which in turn means that the processor has to have more than one program counter, and more than one set of registers. Replicating those resources is less costly than replicating an entire processor. In the MIPS Technologies MIPS32 34K processor, which implements the MIPS MT multithreading architecture, an additional 14% of area can buy an additional 60% of throughput, relative to a comparable single-threaded core.
Multiprocessor architectures are infinitely scalable, in theory, though ultimately with diminishing returns. Each additional processor core on an SoC adds to the area of the chip at least as much as it adds to the performance. Multithreading a single processor can only improve performance up to the level where the execution units are saturated. However, up to that limit, it can provide a “superlinear” payback for the investment in die size.
While the means and the motives are different, multicore systems and multithreaded cores have a common requirement that concurrency in the workload be expressed explicitly by software. If the system has already been coded in terms of multiple tasks on a multitasking operating system, there may be no more work to be done. Monolithic, single-threaded applications need to be decomposed either into subprograms or explicit software threads. This work must be done for both multithreaded and multicore systems, and once completed, either can exploit the exposed concurrency.
When is multicore a good idea?
For embedded SoC designs, a multicore design makes the most sense when the functions of the SoC decompose cleanly into subsystems with a limited need for communication and coordination between them. Instead of running all code on a single high-frequency core connected to a single high-bandwidth memory, assigning tasks to several simpler, slower cores allows code and data can be stored in per-processor memories, each of which has both a lower requirements for capacity and bandwidth. That normally translates into power savings, and potentially in area savings as well, if the lower bandwidth requirements allow for physically smaller RAM cells.
If the concurrent functions of an SoC cannot be decomposed at system design time, an alternative approach is to build a coherent SMP cluster of processor cores. Within such a cluster, multiple processors are available as a pool to run the available tasks, which are assigned to processors on the fly, but this requires a sophisticated interconnect between the cores and a large,r high-bandwidth shared main memory. This negates some of the area and power advantages alluded to above, but can still be a good tradeoff.
Every core represents additional die area, and even in a “powered down” standby state, each dissipates some amount of leakage current, so the number of cores in an SoC design should in general be kept to the minimum necessary to run the target application. There is no point in building a multicore design if the problem can be handled by a single core within the system’s design constraints.
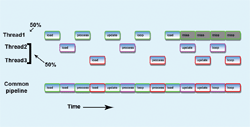
Multithreading can significantly improve pipeline efficiency.
When is multithreading a good idea?
Multithreading makes sense whenever an application with some degree of concurrency is to be run on a processor that would otherwise be stalled a significant portion of the time waiting on memory. This is a function of core frequency, memory technology, and program behavior. Systems where the speeds of processor and memory are so well matched that there is no loss of efficiency due to latency will not get any significant bandwidth improvement from multithreading.
However, the additional resources of a multithreaded processor can be used for other tasks than recovering lost bandwidth. For example, the MIPS MT architecture of the 34K core allows for threads of execution to be suspended, then unblocked directly by external signals to the core, providing for true zero-latency handling of interrupt events. ■
Advertisement
Learn more about MIPS Technologies




