By Majeed Ahmad, contributing writer
Hardware accelerators — specialized devices used to perform specific tasks like classifying objects — are increasingly embedded into system-on-chips (SoCs) serving various AI applications. They help create tightly integrated custom processors that offer lower power, lower latency, data reuse, and data locality.
For a start, it’s necessary to hardware-accelerate the AI algorithms. AI accelerators are specifically designed to enable faster processing of AI tasks; they perform particular tasks in a way that’s not feasible with traditional processors.
Moreover, no single processor can fulfill the diverse needs of AI applications, and here, hardware accelerators incorporated into AI chips provide performance, power efficiency, and latency advantages for specific workloads. That’s why the custom architectures based on AI accelerators are starting to challenge the use of CPUs and GPUs for AI applications.
AI chip designers must determine what to accelerate, how to accelerate it, and how to interconnect that functionality with the neural net. Below is a snapshot of the key industry trends that define the use of hardware accelerators in evolving AI workloads. Inevitably, it begins with AI accelerators available for integration into a variety of AI chips and cards.
AI accelerator IPs
Hardware accelerators are used extensively in AI chips to segment and expedite data-intensive tasks like computer vision and deep learning for both training and inference applications. These AI cores accelerate the neural networks on AI frameworks such as Caffe, PyTorch, and TensorFlow.
Gyrfalcon Technology Inc. (GTI) designs AI chips and provides AI accelerators for use in custom SoC designs through an IP licensing model. The Milpitas, California-based AI upstart offers the Lightspeeur 2801 and 2803 AI accelerators for edge and cloud applications, respectively.
It’s important to note that Gyrfalcon has also developed AI chips around these hardware accelerators, and that makes these AI accelerator IPs silicon-proven. The company’s 2801 AI chip for edge designs performs 9.3 tera operations per second per watt (TOPS/W), while its 2803 AI chip for data-center applications can deliver 24 TOPS/W.
Along with IP development tools and technical documentation, Gyrfalcon provides AI designers with USB 3.0 dongles for model creation, chip evaluation, and proof-of-concept designs. Licensees can use these dongles on Windows and Linux PCs as well as on hardware development kits like Raspberry Pi.
Hardware architecture
The basic premise of AI accelerators is to process algorithms faster than ever before while using as little power as possible. They perform acceleration at the edge, in the data center, or somewhere in between. And AI accelerators can perform these tasks in ASICs, GPUs, FPGAs, DSPs, or a hybrid version of these devices.
That inevitably leads to several hardware accelerator architectures optimized for machine learning (ML), deep learning, natural-language processing, and other AI workloads. For instance, some ASICs are designed to run on deep neural networks (DNNs), which, in turn, could have been trained on a GPU or another ASIC.
What makes AI accelerator architecture crucial is the fact that AI tasks can be massively parallel. Furthermore, AI accelerator design is intertwined with multi-core implementation, and that accentuates the critical importance of AI accelerator architecture.
Next, the AI designs are slicing the algorithms finer and finer by adding more and more accelerators specifically created to increase the efficiency of the neural net. The more specific the use case is, the more opportunities are for the granular use of many types of hardware accelerators.
Here, it’s worth mentioning that besides AI accelerators incorporated into custom chips, accelerator cards are also being employed to boost performance and reduce latency in cloud servers and on-premise data centers. The Alveo accelerator cards from Xilinx Inc., for instance, can radically accelerate database search, video processing, and data analytics compared to CPUs (Fig. 1 ).

Fig. 1: The Alveo U250 accelerator cards increase real-time inference throughput by 20× versus high-end CPUs and reduce sub-2-ms latency by more than 4× compared to fixed-function accelerators like high-end GPUs. (Image: Xilinx Inc.)
Programmability
There are a lot of dynamic changes happening in AI designs, and as a result, software algorithms are changing faster than AI chips can be designed and manufactured. It underscores a key challenge for hardware accelerators that tend to become fixed-function devices in such cases.
So there must be some kind of programmability in accelerators that enables designers to adapt to evolving needs. The design flexibility that comes with programmability features also allows designers to handle a wide variety of AI workloads and neural net topologies.
Intel Corp. has answered this call for programmability in AI designs by acquiring an Israel-based developer of programmable deep-learning accelerators for approximately $2 billion. Habana’s Gaudi processor for training and Goya processor for inference offer an easy-to-program development environment (Fig. 2 ).
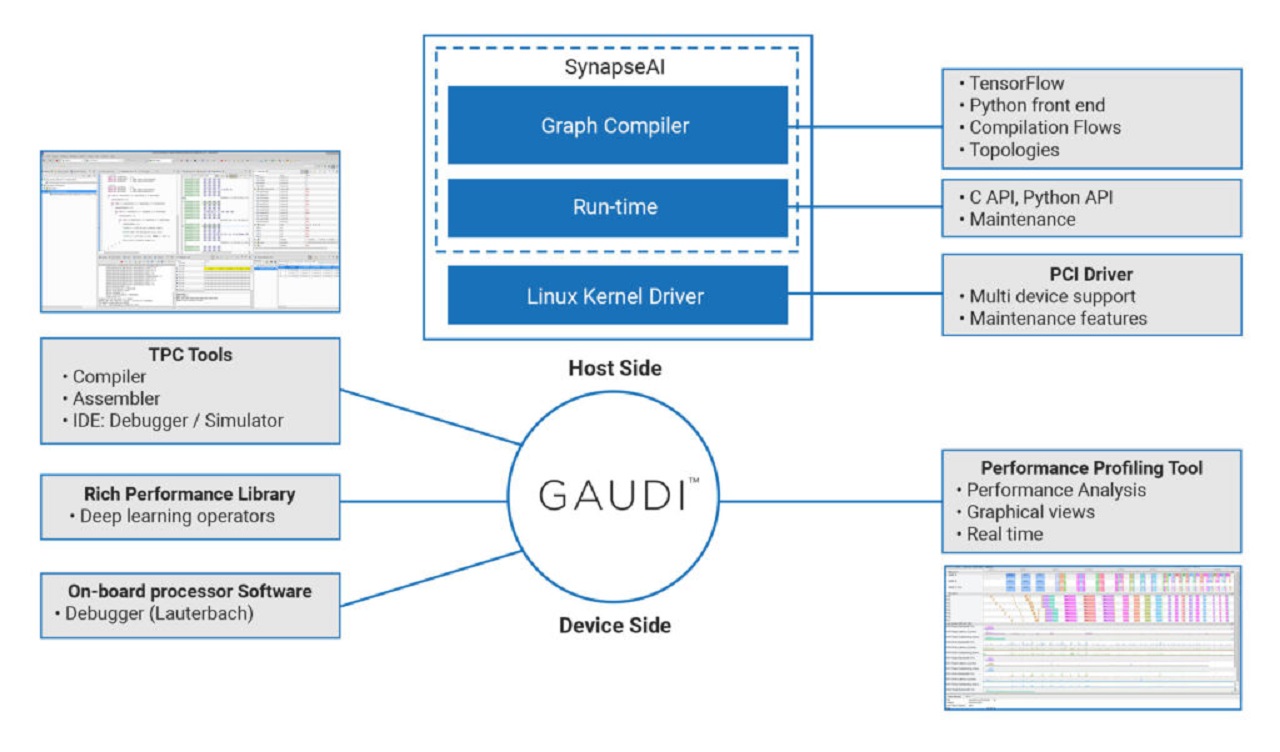
Fig. 2: This is how development platforms and tools speed AI chip designs using the Gaudi training accelerators. (Image: Habana)
AI at the edge
It’s apparent by now that the market for AI inference is much bigger than AI training. That’s why the industry is witnessing a variety of chips being optimized for a wide range of AI workloads spanning from training to inferencing.
That brings microcontrollers (MCUs) into the AI design realm that has otherwise mostly been associated with powerful SoCs. These MCUs are incorporating AI accelerators to serve resource-constrained industrial and IoT edge devices in applications such as object detection, face and gesture recognition, natural-language processing, and predictive maintenance.
Take the example of Arm’s Ethos U-55 microNPU ML accelerator that NXP Semiconductors is integrating into its Cortex-M–based microcontrollers, crossover MCUs, and real-time subsystems in application processors. The Ethos U-55 accelerator works in concert with the Cortex-M core to achieve a small footprint. Its advanced compression techniques save power and reduce ML model sizes significantly to enable execution of neural networks that previously ran only on larger systems.
NXP’s eIQ ML development environment provides AI designers with a choice of open-source inference engines. Depending on the specific application requirements, these AI accelerators can be incorporated into a variety of compute elements: CPUs, GPUs, DSPs, and NPUs.
Advertisement
Learn more about Electronic Products Magazine




