By Jim Harrison
I’m trying to think of an electronic system that could not make use of machine learning. Some very small systems — yes, of course. For some systems, it probably would not be worth the trouble, but for a big percentage of all design projects, machine learning and neural networks (and TensorFlow) could provide a big enhancement.
Last November, Google opened up its in-house machine learning software TensorFlow, making the program that powers its translation services and photo analytics (among many other things) open-source and free to download. And recently, the company released a distributed version of the software that allows it to run across multiple machines — up to hundreds at a time.
Start with neural
A neural network is a technique for building a computer program that learns from data. It is based very loosely on how we think the human brain works. First, a collection of software “neurons” are created and connected together, allowing them to send messages to each other. Next, the network is asked to solve a problem, which it attempts to do over and over, each time strengthening the connections that lead to success and diminishing those that lead to failure.
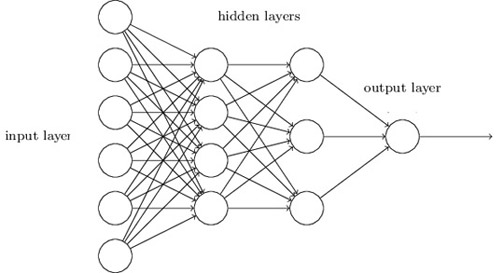
Machine learning
Machine learning software only gets to be clever by analyzing large amounts of data — looking for common properties and trends like facial features in photographs, for example. If you wanted a computer to learn something, you would, using conventional programming, give it a very precise set of rules. Say you want it to cook pasta. There would be, maybe, 50 or 100 rules to find the right pot in the kitchen cupboards, and many more to find the stove and the correct burner, etc. With machine learning, you’d instead show the network 10,000 videos of someone cooking pasta — maybe in the same kitchen, or maybe not.
In recent years, other companies and researchers have also made huge strides in this area of AI, including Facebook, Microsoft, and Twitter. And some have already open-sourced software that’s similar to TensorFlow. This includes Torch — a system originally built by researchers in Switzerland — as well as systems like Caffe and Theano. But TensorFlow is significant. That’s because Google’s AI engine is regarded by some as the world’s most advanced.
Google isn’t giving away all of its secrets. At the moment, the company is only open-sourcing part of this AI engine. It’s sharing only some of the algorithms that run atop the engine. And it’s not sharing access to the remarkably advanced hardware infrastructure that drives this engine. But Google is giving away at least some of its most important data center software.
So what is it exactly?
TensorFlow is an open-source software library for numerical computation using data flow graphs. Nodes in the graph represent mathematical operations, while the graph edges represent the multidimensional data arrays (tensors) communicated between them. The flexible architecture allows you to deploy computation to one or more CPUs or GPUs in a desktop, server, or mobile device with a single API. TensorFlow was originally developed by researchers and engineers working on the Google Brain Team within Google's Machine Intelligence research organization for the purposes of conducting machine learning and deep neural networks research, but the system is general enough to be applicable in a wide variety of other domains as well. See www.tensorflow.org and Github and this video for more information.
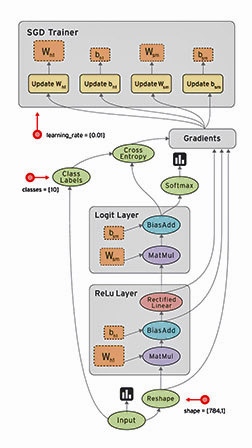
What is a data flow graph?
Data flow graphs describe mathematical computation with a directed graph of nodes and edges. Nodes typically implement mathematical operations, but can also represent endpoints to feed in data, push out results, or read/write persistent variables. Edges describe the input/output relationships between nodes. These data edges carry dynamically sized multidimensional data arrays, or tensors. The flow of tensors through the graph is where TensorFlow gets its name. Nodes are assigned to computational devices and execute asynchronously and in parallel once all of the tensors on their incoming edges becomes available.
Still many limitations
So, basically, you feed neural networks vast amounts of data, and they learn to perform a task. Feed them myriad photos of breakfast, lunch, and dinner and they can learn to recognize a meal. Feed the networks spoken words and they can learn to recognize what you say. Feed them some old movie dialogue and they can learn to carry on a conversation — not a perfect conversation, but a pretty good conversation. GPUs are good at processing lots of little bits of data in parallel, and that’s what deep learning requires.
However, while deep learning has proven to be adept at tasks involving speech and image recognition, it also has plenty of limitations. The answers to most problems are good, but not excellent. Excellent is very, very hard to get to. The intelligence of deep-learning techniques is narrow and stiff. As cognitive psychologist Gary Marcus writes in The New Yorker, the popular methods “lack ways of representing causal relationships (such as between diseases and their symptoms) and face challenges in acquiring abstract ideas like ‘sibling’ or ‘identical to.’ They have no obvious ways of performing logical inferences, and they are also still a long way from integrating abstract knowledge, such as information about what objects are, what they are for, and how they are typically used.” In other words, they don’t have any common sense.
Advertisement




