By Richard Quinnell, Editor-in-Chief
The success of personal assistants that you interact with via the spoken word, such as Amazon’s Alexa, Apple’s Siri, and Google Home, has made voice control a hot-ticket item in system design. Getting started in this technology, though, has required significant audio and signal processing expertise to address issues in background noise and the speaker’s location. A new development kit from Microsemi, in partnership with Amazon’s Alexa voice service (AVS), seeks to simplify startup so developers can focus on application rather than implementation.
The AcuEdge development kit is a starting point for developers working on voice-activated systems but is not an out-of-the-box system. The kit contains a development module based on Microsemi’s ZL38063 Timberwolf audio processor preloaded with the company’s license-free AcuEdge audio processing software. There is also a cylindrical mounting frame to carry the electronics, looking a lot like the skeleton of an Amazon Echo. Developers, however, need to supply their own Raspberry Pi 3 or a similar processor board of their choice, to which the development board mounts. Developers also need a speaker to deliver the audio from AVS. Speaker choice is open for developers, but the frame is sized for a JBL Clip portable speaker.

Fig. 1: AcuEdge Alexa development kit from Microsemi.
Once the hardware is assembled, the next thing needed is a developer’s account with Amazon AVS. The account is free, however, and enjoys substantial support from Amazon for everything from technical training to product marketing guidelines. Then power up the hardware, install the software from Microsemi’s github, start up the Alexa service, and start talking with Alexa.
The development board includes two microphones so that echo-cancelling and beam-forming algorithms in the AcuEdge software package allow either 180° or 360° “listening” for user voice. The beamforming can localize the user to a 20° window to help reject noise from outside sources. The software is also able to support full duplex voice interaction. This full duplex allows, among other things, for the system to actively noise-cancel its own output audio so that it can better respond to users trying to talk over the system’s response.
With this kit, developers are able to quickly start working on applications that leverage rapidly growing consumer interest in speech control. According to Microsemi, the market for voice-enabled systems is expected to be 75 million units annually within five years, with two-thirds of those being digital assistants like Echo. Applications such as lighting systems, appliances, set-top boxes, and the like form an even larger market for voice activation features.
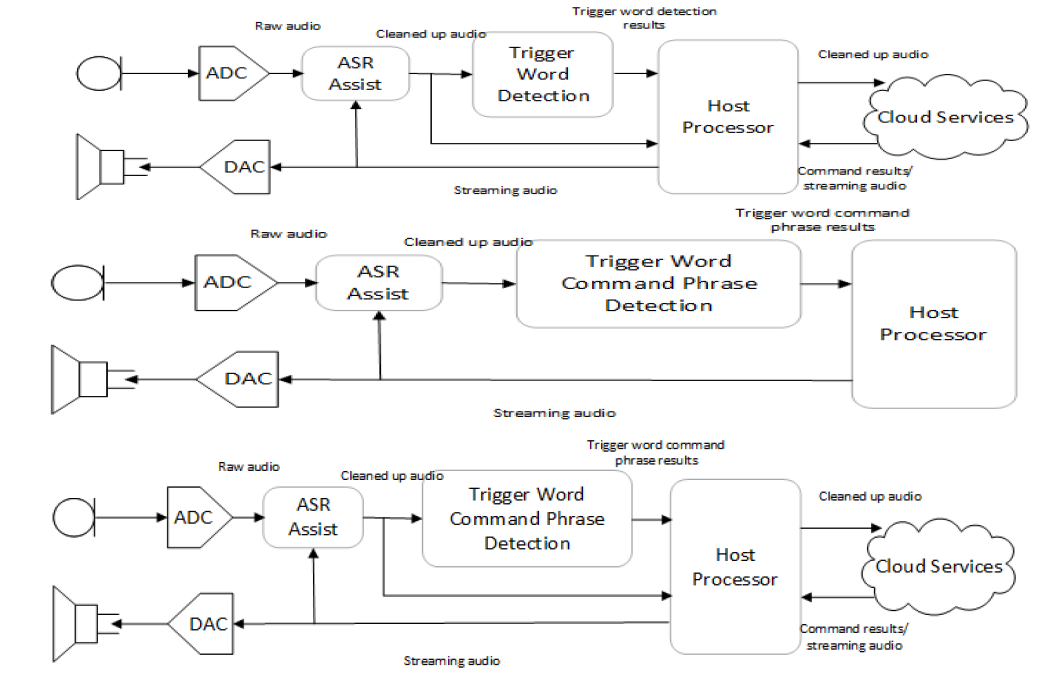
Fig. 2: Possible voice activation architectures. Image source: Microsemi.
While the kit serves as an entry point for designing a voice-activated system, it only represents one of three potential architectures that developers can pursue. This system uses on-board processing to identify a wake-up word, then sends further audio data to the cloud-based AVS for processing of the commands that follow. An alternative architecture provides more limited word recognition built in so that no cloud connection is needed for the device to respond to commands. Hybrid systems provide a third alternative, using a cloud connection to offer full voice functionality with on-board recognition of basic commands as a backup. The Timberwolf processor can serve as an audio front-end processor for any of those architectures.
Advertisement
Learn more about Electronic Products Magazine




