The National Security Agency uses metadata to recognize and classify terrorists to kill them. But recently, a new investigation of the former published Snowden documents suggests that several of those people may have been innocent.

Last May, detailed documents revealing the NSA’s SKYNET program were published, showing its engagement in mass surveillance of Pakistan’s mobile phone network. SKYNET uses a machine learning algorithm on the mobile network metadata of 55 million people to analyze and rate the individual’s likeliness of being a terrorist.
But, according to Patrick Ball, a data scientist and the director of research at the Human Rights Data Analysis Group, a flaw in how the NSA trains SKYNET’s machine learning algorithm could make the results scientifically unsound.
Since 2004, approximately 2,500 and 4,000 people have been killed by drone strikes in Pakistan, with many of them being classified as “extremists” by the government. SKYNET’s unreliable algorithm is believed to have mislabeled thousands of innocent people between 2007, the onset of its development, and the present.
SKYNET operates similar to a modern Big Data business application, collecting metadata and storing it on NSA cloud servers, extracting relevant information, and then applying machine learning to identify outliers, or in this case, target people. In addition to collecting DNR (Dialed Number Recognition data, including who called whom, time, duration, etc.), SKYNET also retrieves the user’s location, allowing for the creation of detailed traveling information. Those who deactivate their mobile phone or swap SIM cards get flagged for evading mass surveillance. Even handset swapping gets detected and flagged.
The program pieces together people’s typical routines, noting those who travel together, have shared contacts, stay overnight with friends, visit other countries, or permanently move. Overall, SKYNET uses more than 80 different properties to determine the probability of being a terrorist. It’s based on the assumption that the behavior of terrorists differs significantly from those of ordinary citizens, as determined by data-driven statistics.
Training the machine is similar to training a spam filter: you feed it known non-spam and known spam to learn how to filter it correctly. A critical aspect in training SKYNET is to differentiate its recognition of known terrorists to teach the algorithm to properly spot similar profiles.
However, the problem is that there are few known terrorists that are likely to answer a hypothetical NSA survey that can be used to feed the algorithm. Internal NSA documents suggest SKYNET uses a set of “known couriers” as ground truths, and it then assumes the rest of the population by default is innocent.
SKYNET’s classification algorithm analyzes the metadata and ground truths, and produces a score for each individual with the objective to assign high scores to real terrorists and low scores to innocent people.
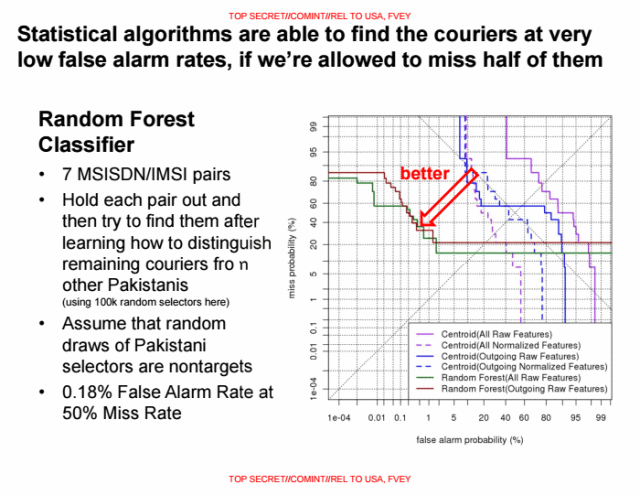
To do so, the SKYNET algorithm uses the random forest algorithm, which takes random subsets of the training data to create a “forest” of decision “trees,” and then combines those by averaging the predictions from the individual trees. SKYNET’s algorithm takes the 80 properties of each mobile device user and assigns them to a numerical score, similar to a spam filter.
From there, it selects a threshold value above which a user is classified as a “terrorist.” In a slide demonstration, the NSA presents the evaluation results when the threshold is set to a 50 percent false negative rate. This means half of the people who would be classified as “terrorists” are instead categorized under innocent, to keep the number of false positives (innocents falsely classified as terrorists) as low as possible.
We can’t be sure that the 50 percent false negative rate chosen for the presentation is the same threshold used to produce the final kill list. The issue of what to do with innocent false positives continues to remain.
“The reason they're doing this,” Ball explained, “is because the fewer false negatives they have, the more false positives they're certain to have. It's not symmetric: there are so many true negatives that lowering the threshold to reduce the false negatives by 1 will mean accepting many thousands of additional false positives. Hence this decision.”
The major concern is how the NSA trains the algorithm with ground truths. It evaluates the SKYNET program using 100,000 randomly selected people identified by their mobile phones, and a known group of seven terrorists. The NSA trained the learning algorithm by feeding it six of the terrorists’ behavioral patterns and asking SKYNET to find the seventh. This data then provides the percentages of false positives.
“First, there are very few 'known terrorists' to use to train and test the model,” Ball said. “If they are using the same records to train the model as they are using to test the model, their assessment of the fit is completely bullshit. The usual practice is to hold some of the data out of the training process so that the test includes records the model has never seen before. Without this step, their classification fit assessment is ridiculously optimistic.”
The 100,000 citizens are selected at random, while the seven terrorists are from a known cluster. Under a random selection of a tiny subset of less than 0.1 percent of the total population in Pakistan, the density of the social graph of citizens is reduced massively, while the terrorist cluster remains tightly interconnected. A scientifically-sound statistical analysis would require the NSA to mix the terrorists into the population set before randomly selecting a subset. While it may not sound like much, this is highly damaging to the quality of the results and the accuracy of the classification and assassination of people labeled as “terrorists.”
“Government uses of big data are inherently different from corporate uses,” security guru Bruce Schneier said. “The accuracy requirements mean that the same technology doesn't work. If Google makes a mistake, people see an ad for a car they don't want to buy. If the government makes a mistake, they kill innocents.”
Source: Ars Technica
Advertisement
Learn more about Electronic Products Magazine




