Sally Ward-Foxton, European correspondent – EETimes
A novel neural network developed at the University of Surrey for the re-identification of people in video surveillance footage is small enough to be deployed on edge devices such as security cameras, its inventors say. They also claim it is more adept at the task than human camera operators.
The new neural network, OSNet, uses 2.2 million parameters, a very small number in the context of deep learning. Many other person re-identification (ReID) networks are based on the classic image recognition algorithm ResNet-50, which uses 24 million parameters.
This means it can be done on the edge, instead of in the cloud, which would save bandwidth that otherwise would have been consumed by transmitting large quantities of video footage to the data centre.
The research was carried out at the University of Surrey’s Centre for Vision, Speech and Signal Processing (CVSSP). ReID is a desired feature for multi-camera surveillance systems which track people as they pass between different non-overlapping camera views. It’s a particularly difficult problem since the viewing conditions for individual cameras can be quite different. The typical distances between the subject and the camera in surveillance footage complicates problem, because the clothing worn by different people can appear very similar.

Person ReID is a difficult problem. Each triplet shows, from left to right, the original image, a match, and a false match. (Image: University of Surrey)
“With OSNet, we set out to develop a tool that can overcome many of the person re-identification issues that other setups face, but the results far exceeded our expectations. The ReID accuracy achieved by OSNet has clearly surpassed that of human operators,” said Tao Xiang, Distinguished Professor of Computer Vision and Machine Learning at CVSSP. “OSNet not only shows that it’s capable of outperforming its counterparts on many re-identification problems, but the results are such that we believe it could be used as a stand-alone visual recognition technology in its own right.”
In their paper “Omni-Scale Feature Learning for Person Re-Identification,” the researchers say that despite its small model size, OSNet achieves state of the art performance on six person ReID datasets, outperforming most large-size models, often by a clear margin.
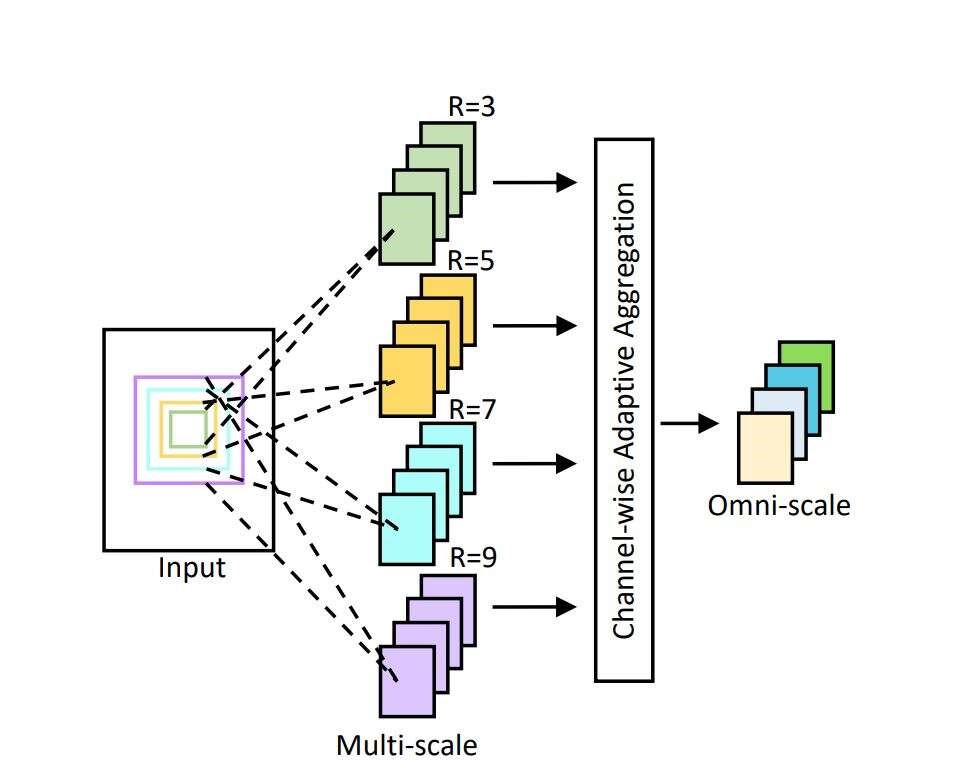
The structure of OSNet, where R is the receptive field size. (Image: University of Surrey)
OSNet is based on combining information from a variety of spatial scales. Features corresponding to small, local regions (shoes, glasses), and global whole body regions (person’s size and age, rough clothing combinations like white T-shirt and grey shorts) are considered. First, the search is narrowed down using the whole-body features such as clothing combinations, then the local features are inspected, such as whether the shoes are a match.
For challenging cases (such as (d) in the above image), more complicated features that span multiple scales are required. The example the researchers give is a logo on a T-shirt, which could be mistaken for many other patterns from this distance. It’s the combination of the logo (small scale) plus the white T-shirt (medium scale) that makes the feature most effective.
OSNet achieves this effective combination of features from multiple scales using multiple convolutional streams, each detecting features at a certain scale. The resulting multi-scale feature maps are dynamically fused by weights generated by a novel unified aggression gate (a trainable mini-network sharing parameters across all streams), which can single out features from any particular scale or mix features from different scales, as necessary.
The article originally published at sister publication EE Times.
Advertisement
Learn more about Electronic Products Magazine




