Choosing new load sharing and selective tripping techniques to increase UPS reliability
BY DAVID CHETHAM-STRODE
Hewlett-Packard
Palo Alto, CA
www.hp.com/go/rackandpower
The greening of data centers is dominating headlines, but the number one concern for IT managers with regard to power still remains the issue of reliability. There are numerous UPS designs to choose from for optimal performance, but maximum reliability still goes hand-in-hand with redundancy. The following unique paralleling design enables paralleling for redundancy or capacity with no inter-module control synchronization scheme.
Less circuitry is more
In this particular design, the modules are completely autonomous, see Figure 1. The only area common among them is the input and output power bus. Synchronization between modules relies on mathematical algorithms written into the firmware to keep all systems operating in unison. This design is more reliable than legacy paralleling methods because each module controls itself, with no need for additional signals from a master system. Since there is no additional complex circuitry or additional system wiring, installation and operation of the system is simplified and inherently more reliable. It is important to note that since the solution is implemented intrinsically, the controls of the individual modules do not need to know whether or not they are even in parallel.
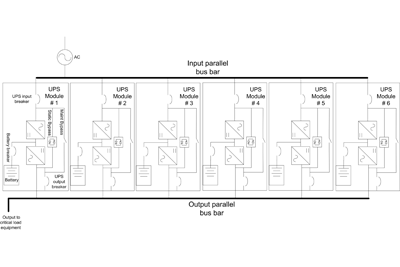
Fig. 1. Completely autonomous modules via firmware with no additional circuitry.
This firmware-based approach allows paralleling multiple modules for either redundancy, capacity or a combination of both. The UPS firmware design provides a proven path to uniquely share load and remove (selective-trip) faulty modules from the parallel power bus without affecting the connected critical load equipment.
Redundancy for reliability
It is apparent when reviewing MTBF calculations that a parallel redundant UPS solution increases reliability and maximizes availability. Using a paralleling technique that allows each module in a system to be a true “peer” to other paralleled modules, increases these values dramatically. Each UPS module monitors itself for any type of failure condition and takes itself off line if warranted.
As shown in Figure 1, each UPS module has all the features needed for operation as a stand-alone UPS. Each UPS has logic control, rectifier, inverter, input breaker, batteries, battery breaker, emergency bypass circuit (static bypass), and maintenance bypass system Redundancy in components brings benefits in reliability as no one component is a single failure point.
In a modular redundant parallel design you also want to be able to repair any system while the critical load is still supported. This requires hot swappable components, where individual failed parts, or parts identified in the control logic as approaching a failure point, can be replaced while the system is operating. The design shown in figure 1 includes hot swappable electronics and battery modules. Also to speed repairs, the electronics module contains all major systems which are calibrated and tested to work together to eliminate the need for field calibration when a part is replaced. This type of design vastly increases system availability by further reducing MTTR (mean time to repair).
Automatic load sharing
In an optimum parallel configuration, the UPS modules should always share the load equally, which is particularly important as more modules are paralleled together. The load is shared equally between modules through synchronization of output AC power waveforms (see Figure 2). If any system loses synchronization between modules, the shared load becomes severely unbalanced, typically resulting in the entire system trying to go to emergency bypass, and in many cases causing the critical load to lose AC power. As small as a one degree phase difference between two UPS modules results in a fifty percent load imbalance.
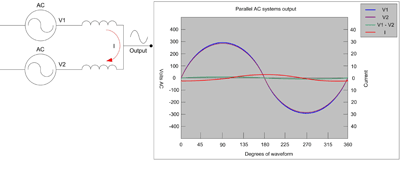
Fig. 2. Synchronization of output ac power waveforms.
In legacy paralleling designs a “master” controller with a single communication bus controls the synchronization and load sharing between individual power modules. If this controller fails, it attempts to give control to a “back-up” controller. However certain failure modes could even affect the backup, forcing a system crash. These designs use either internal or external wiring to ensure synchronization between parallel systems while operating. If any part of the communication link fails, so does the system — constituting a single-point-of-failure.
The design shown above in Figure 1 eliminates the necessity for inter-module synchronization and wiring, providing a true peer-to-peer relationship. Each UPS module runs load share control algorithms which maintain synchronization and load balance by constantly making minute adjustments to variations in the output power requirements. The modules conform to demand and are not in conflict with each other for the load. Such precise load share control is possible because this UPS design deploys a digital signal processing technique known as direct digital synthesis to control inverter frequency. There are also other parameters that must be addressed to effectively and seamlessly share the load between paralleled modules including:
Power backfeed under imperfect sharing at light or no loadPower backfeed with 100% load removalOscillation of source frequencyIndependent judgment of source availability
All of these will affect the operation of the load share function. A careful selection of priority and gain is necessary so that the action taken by each module is the one most beneficial to the mission, therefore ensuring uninterrupted operation.
Selective tripping
Eventually a component within a module may fail. If the component failure results in the module’s inability to support the critical bus within specification limits, the failed module must remove itself from the critical bus. Each module in a paralleled system employs a unique selective tripping approach which consists of a two-part process:
Identification of a module output condition which is out of specification limitsRemoval of the faulty module from the critical bus
As with load sharing, each module need look only at itself to determine if it has failed. This approach eliminates the need to identify which module is faulty from a system level, which is a common issue for legacy parallel redundant systems. By not relying on communication links between the modules, there are no time lapses between the time a failure occurs and the time the module is removed from the critical bus. Since each module monitors itself for a failure, the faulty module need only isolate itself from the critical bus when a failure is detected.
To identify a module failure, the selective trip method looks for changes in module output voltage and output current data relative to recent output current and voltage data. The controls within each module store the output current and voltage waveforms on each of the three phases for the last five cycles. The moving average of the last five cycles (Ia & Va ) is compared with the present waveforms (In and Vn ). From this information the module calculates the change in current and voltage (∆I and ∆V) (∆I = In – Ia and ∆V = Vn – Va ). The magnitude and sign (positive or negative) of the product of ∆I x ∆V determine if a module is to be isolated from the critical bus or if it should continue functioning in normal operation.
With the loss or removal of one module, no other actions need occur at the module or system level for the remaining module(s) to assume the balance of the full load. In redundant systems the selective tripping of one module is highly reliable, instantaneous, and uninterrupted, avoiding even a momentary drop in the critical bus voltage.
To get the maximum availability, reliability and flexibility you need to look for a paralleling design which promotes a peer-to-peer relationship between modules. Legacy designs using a master control with a backup can be more complex to install and are prone to single points of failure which could jeopardize the mission of protecting the critical loads.
■
Advertisement
Learn more about Hewlett-Packard




