Nvidia has claimed performance records with its AI computing platform in the latest round of MLPerf AI inference benchmarks. MLPerf is the industry’s independent benchmark consortium that measures AI performance of hardware, software, and services. For data center and edge computing systems, Nvidia is the performance leader in all six application areas in the second round of MLPerf scores.
The MLPerf consortium released results for the MLPerf Inference v0.7, the second round of submissions to its machine-learning inference performance benchmark suite, which doubles the number of applications in the suite. It also introduces new MLPerf Mobile benchmarks. The MLPerf Mobile working group, led by Arm, Google, Intel, MediaTek, Qualcomm, and Samsung Electronics, selected four new neural networks for benchmarking and developed a smartphone application.
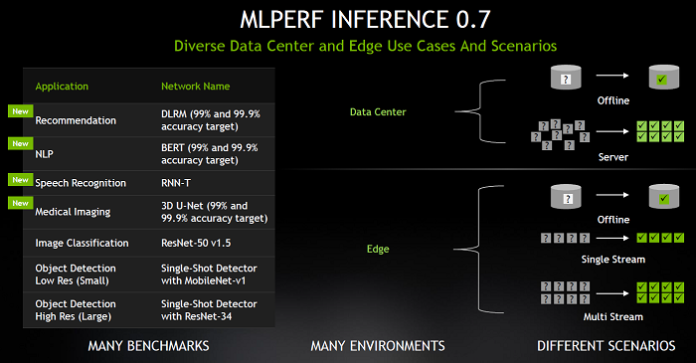
MLPerf also added additional tests for data centers and edge systems, expanding beyond the original two for computer vision, to include four new areas of AI: recommendation systems, natural-language understanding (NLP), speech recognition, and medical imaging, along with image classification (ResNet-50) and objection detection (low- and high-res). The four new AI inference benchmarks are Deep Learning Recommendation Model (DLRM), Bi-directional Encoder Representation from Transformers (BERT), Recurrent Neural Network Transducer (RNN-T), and 3D U-Net.
The tests
This is the second round of MLPerf AI inference tests, and it was eagerly anticipated for a few reasons, said Paresh Kharya, senior director of product management, Accelerated Computing, Nvidia. The benchmark has evolved to incorporate new application areas, and there was a larger participation overall from 12 submitters in the last round (MLPerf 0.5 Inference) to 23 submitters in this round (MLPerf 0.7 Inference), and Nvidia Ampere competed on these tests for the first time, he added.
“The four new application areas are recommendation systems with a model called DLRM that was contributed by Facebook, a very important NLP model contributed by Google, a speech-recognition model called RNN-T, and, finally, a new medical imaging model called 3D U-Net that is used to identify tumors in MRI scans,” said Kharya. “The revamped benchmarks represent modern use cases, and there are different environments and scenarios that you can run these tests for.”
Source: Nvidia (Click for larger image.)
Nvidia submitted for data center and edge applications, and there are four different scenarios that underline these environments, Kharya explained.
“There are offline tests, which means you have data sitting in your storage, and the task is to run as many inferences as possible,” he said. “Then you have server scenarios that represent different users hitting the data center servers, representing internet applications or applications delivered from the cloud, and the task is to do as many inferences as possible with the load that’s coming in.”
There also are single-stream and multi-stream scenarios submitted for the data center and edge environments, he added.
Scores are based on systems. Commercially available systems using Nvidia’s A100 GPUs, ranked No. 1 across all AI inference benchmark scores, said Nvidia. In addition, Nvidia’s GPUs dominated the submissions, with Nvidia and 11 partners submitting more than 85% of systems. Partners include Cisco, Dell, and Fujitsu.
Five years ago, only a handful of leading high-tech companies used GPUs for inference, said Nvidia, and now the AI inference platform is available through every major cloud and data center infrastructure provider, across a range of industries.
The scores
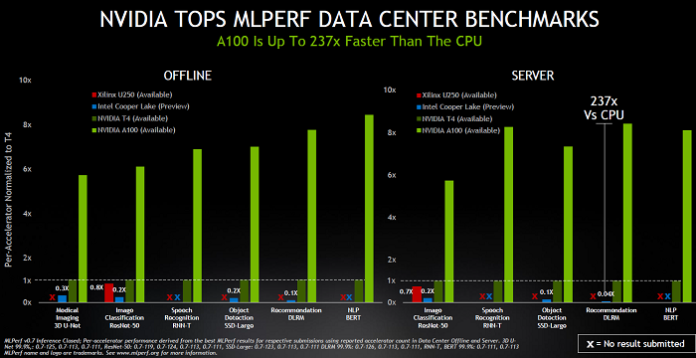
Nvidia and its partners submitted their MLPerf 0.7 results based on Nvidia’s acceleration platform, which includes Nvidia data center GPUs, edge AI accelerators, and optimized software. Nvidia A100, featuring third-generation Tensor Cores and Multi-Instance GPU technology, increased its lead on the ResNet-50 test, beating CPU-only systems by 30× versus 6× in the last round.
For the two data center scenarios, offline and server, Nvidia outperformed the competition by a large margin on every test. However, Kharya noted that there was no Google TPU submission, and many startups that have been making a lot of claims around inference performance are also missing from the standardized tests.
Source: Nvidia (Click for larger image.)
The MLPerf Inference 0.7 benchmarks also show that the A100 outperformed CPUs by up to 237× in the newly added recommender test for data center inference. This means a single Nvidia DGX A100 system can provide the same performance as 1,000 dual-socket CPU servers, said Nvidia, offering customers cost efficiency when taking their AI recommender models from research to production.
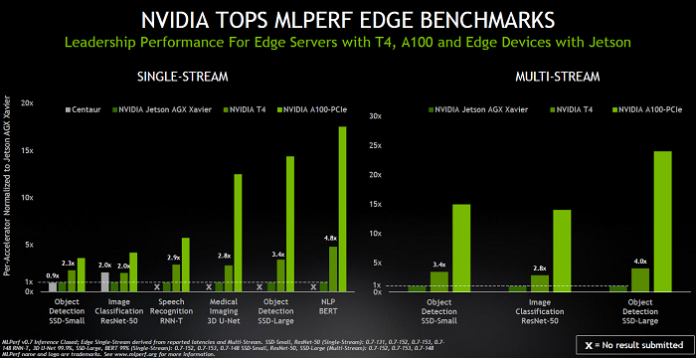
Similarly, in edge scenarios, where there are single-stream and multi-stream tests, Nvidia submitted its T4 and A100 PCIe GPUs and Jetson Xavier SoCs. The benchmarks show that Nvidia T4 Tensor Core GPU beat CPUs by up to 28× in the same tests, and its Nvidia Jetson AGX Xavier is the performance leader among SoC-based edge devices.
“Both the Nvidia Jetson Xavier, a 30-W SoC chip, and our GPUs outperformed the competition by a big margin across the different tests in their respective categories,” said Kharya. (See chart below.)
Source: Nvidia (Click for larger image.)
From research to production
Performance breakthroughs are so vital for the adoption of AI, said Kharya. “AI is already achieving results that no human-written software can. AI is very scalable. Larger and more complex models create more capable AI and AI that’s more accurate, and it can perform many different tasks.”

Source: Nvidia (Click for larger image.)
However, there are challenges, he said. “The more accurate AI, the more complex it is not to just train but also to run inference on. The complexity of models has grown 30,000× in the last five years. When these accurate models are deployed in real applications, you need extremely high inference performance in order to make those applications even possible, so millions of medical scans that are being taken every day can be accurately diagnosed in real time for diseases, or hundreds of millions of conversational AI interactions can feel natural from customer support to users searching and finding information.
“And also content and product recommendations that are highly relevant can now be personalized and delivered to users,” Kharya added.
Nvidia has increased its leadership over CPUs, increasing from about 6× to 30× on a basic computer vision model (ResNet-50), and on advanced recommendation system models, which is newly added to this round, the Nvidia A100 is 237× faster than the Cooper Lake CPU, said Kharya.
This translates into a single DGX A100 providing the same performance on recommendation systems as 1,000 CPU servers, he claimed. “The latest results on MLPerf is really a great proof point on how we are continuing to not just widen our performance lead but ultimately provide increasing value to our customers and make a whole new range of AI applications from research to production possible.”
Although the GPU architecture is the foundation for Nvidia’s AI platform, it also requires a highly optimized software stack. For inference, Nvidia breaks it down into four key steps: pre-trained AI models (available through Nvidia’s NGC hub for GPU-accelerated software), Transfer Learning Toolkit to optimize the models, Nvidia TensorRT inference optimizer with over 2,000 optimizations, and the Nvidia Triton inference serving software to run the models and applications.
Source: Nvidia (Click for larger image.)
The company also offers end-to-end application frameworks for key application areas. They include CLARA (health care), DRIVE (autonomous vehicles), JARVIS (conversational AI), ISAAC (robotics), MERLIN (recommendation systems), and METROPOLIS (smart cities).
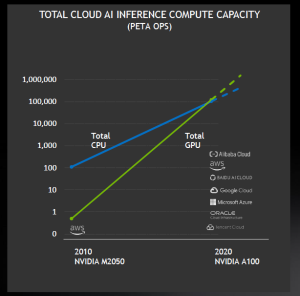
Nvidia also claimed that its GPUs offer more AI inference capacity in the public cloud than CPUs. The total cloud AI inference compute capacity on Nvidia GPUs is growing roughly 10× every two years, according to the company. Applications range from autonomous drones and delivery robots to warehouses and optical inspection.
From 2010 to 2020, Nvidia has exceeded the aggregate amount of GPU compute in the cloud compared with all of the cloud CPUs, said Kharya. “We are past the tipping point for GPU-accelerated AI inference.”
Advertisement
Learn more about NVIDIA






